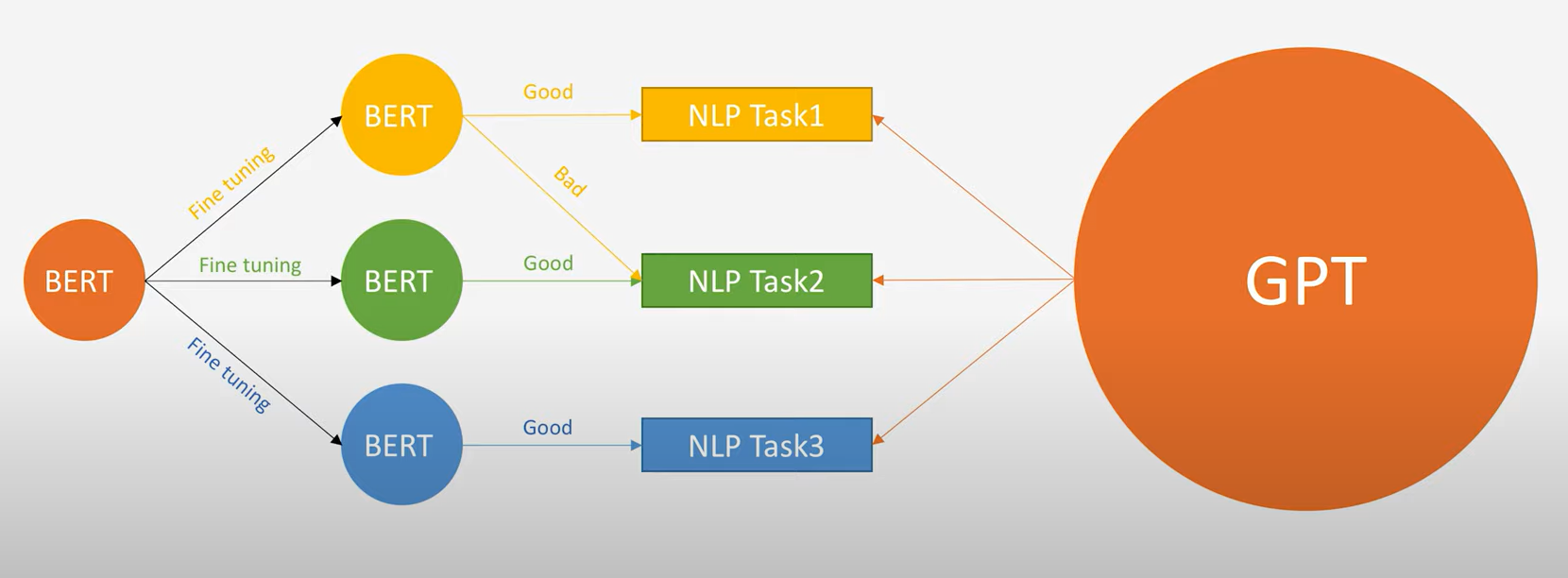
> 트랜스퍼 러닝
트랜스퍼 러닝
: 특정 태스크를 학습한 모델을 다른 태스크 수행에 재사용하는 기법.

- 태스크1: 업스트림 태스크(ex. 다음 단어 맞히기, 빈칸채우기 등) / 태스크2: 다운스트림 태스크(ex. 문서 분류, 개체명 인식 등)
- 프리트레인: 업스트림 태스크를 학습하는 과정
< 장점 >
- 기존보다 모델의 학습 속도가 빨라지고 새로운 태스크를 더 잘 수행하는 경향이 있다.
업스크림 태스크
< GPT vs BERT >
대표적인 태스크 가운데 하나가 다음 단어 맞히기 입니다. GPT 계열 모델이 바로 이 태스크로 프리트레인을 수행합니다. 예를 들어 티끌 모아라는 문맥이 주어졌고 학습 데이터 말뭉치에 티끌 모다 태산이라는 구가 많다고 하면 모델은 이를 바탕으로 다음에 올 단어를 태산으로 분류합니다.
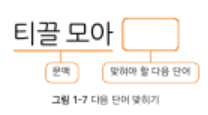
=> 다음 단어 맞히기로 업스트림 태스크를 수행한 모델을 언어 모델이라고 합니다.
다른 업스트림 태스크로는 빈칸 채우기가 있습니다. BERT 계열 모델이 바로 이 태스크로 프리트레인을 수행합니다.

=> 빈칸 채우기로 업스트림 태스크를 수행한 모델을 마스크 언어 모델이라고 합니다.
< 지도 학습 vs 자기지도 학습 >
- 지도 학습: 사람이 만든 정답 데이터로 모델을 학습하는 방법
- 자기지도 학습: 데이터 내에서 정답을 만들고 이를 바탕으로 모델을 학습하는 방법 ( ex. 워드 임베딩 알고리즘, BERT와 같은 언어 모델의 학습 방법)
다운스트림 태스크
- 파인튜닝: 다운스트림 태스크의 학습 방식, 프리트레인을 마친 모델을 다운스트림 태스크에 맞게 업데이트하는 기법.
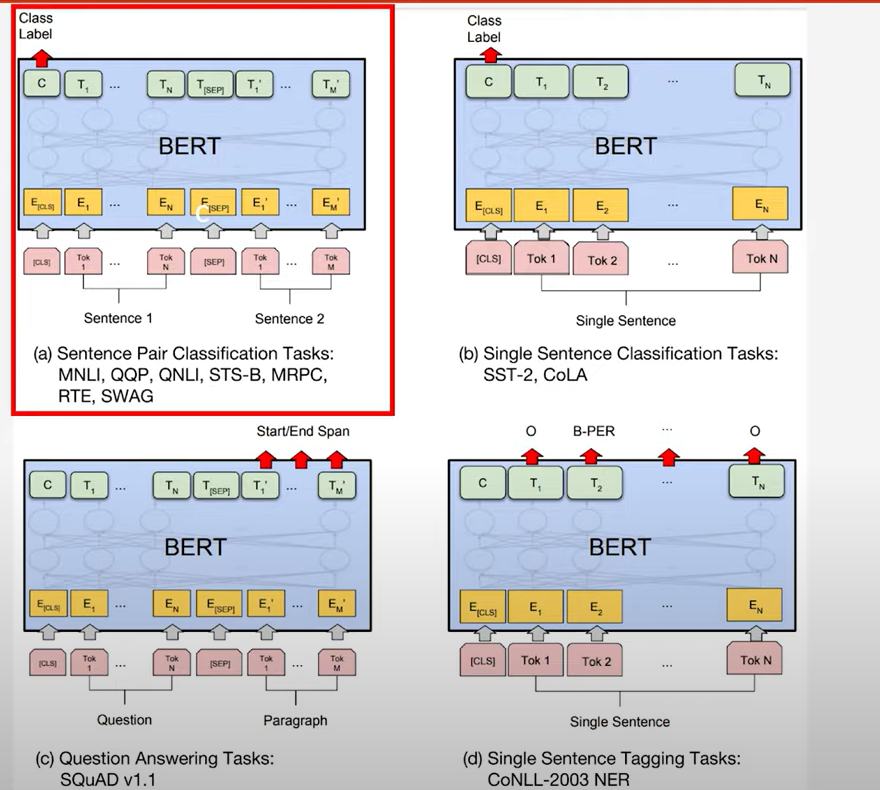
< 문서 분류 >
: 자연어를 입력받아 해당 입력이 어떤 범주(긍정, 중립, 부정 따위)에 속하는지 그 확률값을 반환합니다.

< 자연어 추론 >
: 문장 2개를 입력받아 두 문장 사이의 관계가 참, 거짓, 중립 등 어떤 범주인지 그 확률값을 반환합니다.

< 개체명 인식 >
: 자연어를 입력받아 단어별로 기관명, 인명, 지명 등 어떤 개체명 범주에 속하는지 그 확률값을 반환합니다.

< 질의 응답 >
: 자연어( 질문 + 지문 )를 입력받아 각 단어가 정답의 시작일 확률값과 끝일 확률값을 반환합니다.

< 문장 생성 >
: GPT 계열 언어 모델이 널리 쓰입니다. 문장 생성 모델은 자연어를 입력받아 어휘 전체에 대한 확률값을 반환합니다.

+ 참고 +

> 학습 파이프라인 소개
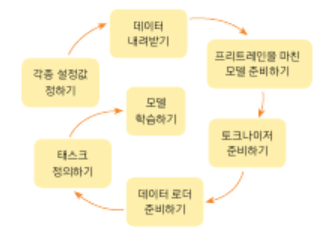
- Step 1. 주어진 데이터를 훈련 데이터, 검증 데이터, 테스트 데이터로 나눈다. 가령, 6:2:2 비율로 나눌 수 있다.
- Step 2. 훈련 데이터로 모델을 학습한다. (에포크 +1)
- Step 3. 검증 데이터로 모델을 평가하여 검증 데이터에 대한 정확도와 오차(loss)를 계산한다.
- Step 4. 검증 데이터의 오차가 증가하였다면 과적합 징후이므로 학습 종료 후 Step 5로 이동, 아니라면 Step 2.로 재이동한다.
- Step 5. 모델의 학습이 종료되었으니 테스트 데이터로 모델을 평가한다
> 머신 러닝 개요
: 딥 러닝을 포함하고 있는 것
머신 러닝 모델의 평가
- 하이퍼파라미터: 모델의 성능에 영향을 주는 사람이 값을 지정하는 변수
- 매개변수: 가중치와 편향, 학습을 하는 동안 값이 계속해서 변하는
분류와 회귀
1) 이진 분류 문제
: 주어진 입력에 대해서 두 개의 선택지 중 하나의 답을 선택해야 하는 경우를 말합니다.
2) 다중 클래스 분류
: 주어진 입력에 대해서 세 개 이상의 선택지 중에서 답을 선택해야 하는 경우를 말합니다.
3) 회귀 문제
: 정답이 몇 개의 정해진 선택지 중에서 정해져 있는 경우가 아니라 어떠한 연속적인 값의 범위 내에서 예측값이 나오는 경우를 말합니다.
활성화 함수
- 은닉층: 대부분 렐루 함수(ReLU) 나 리키 렐루(Leaky ReLU)를 쓴다.
- 출력층: 이진 분류일때는 시그모이드 함수, 다중 클래스 분류일때는 소프트맥스 함수를 사용한다.
> CNN 모델
1) 합성곱 연산이란?
: 합성곱 필터로 불리는 특정 크기의 행렬을 이미지 데이터 ( 혹은 문장 데이터 ) 행렬에 슬라이딩하면서 곱하고 더하는 연산을 의미합니다.

입력 데이터 크기와 패딩, 스트라이드 값에 의해 출력 데이터의 크기가 결정됩니다.
2) 풀링 연산
: 합성곱 연산 결과로 나온 특징맵의 크기를 줄이거나 주요한 특징을 추출하기 위해 사용하는 연산입니다.
+ 참고 코드 +
| # 필요한 모듈 임포트 |
| import pandas as pd |
| import tensorflow as tf |
| from tensorflow.keras import preprocessing |
| from tensorflow.keras.models import Model |
| from tensorflow.keras.layers import Input, Embedding, Dense, Dropout, Conv1D, GlobalMaxPool1D, concatenate |
| # 데이터 읽어오기 |
| train_file = "./chatbot_data.csv" |
| data = pd.read_csv(train_file, delimiter=',') |
| features = data['Q'].tolist() |
| labels = data['label'].tolist() |
| # 단어 인덱스 시퀀스 벡터 |
| corpus = [preprocessing.text.text_to_word_sequence(text) for text in features] |
| tokenizer = preprocessing.text.Tokenizer() |
| tokenizer.fit_on_texts(corpus) |
| sequences = tokenizer.texts_to_sequences(corpus) |
| word_index = tokenizer.word_index |
| MAX_SEQ_LEN = 15 # 단어 시퀀스 벡터 크기 |
| padded_seqs = preprocessing.sequence.pad_sequences(sequences, maxlen=MAX_SEQ_LEN, padding='post') |
| # 학습용, 검증용, 테스트용 데이터셋 생성 ➌ |
| # 학습셋:검증셋:테스트셋 = 7:2:1 |
| ds = tf.data.Dataset.from_tensor_slices((padded_seqs, labels)) |
| ds = ds.shuffle(len(features)) |
| train_size = int(len(padded_seqs) * 0.7) |
| val_size = int(len(padded_seqs) * 0.2) |
| test_size = int(len(padded_seqs) * 0.1) |
| train_ds = ds.take(train_size).batch(20) |
| val_ds = ds.skip(train_size).take(val_size).batch(20) |
| test_ds = ds.skip(train_size + val_size).take(test_size).batch(20) |
| # 하이퍼파라미터 설정 |
| dropout_prob = 0.5 |
| EMB_SIZE = 128 |
| EPOCH = 5 |
| VOCAB_SIZE = len(word_index) + 1 # 전체 단어 수 |
| # CNN 모델 정의 |
| input_layer = Input(shape=(MAX_SEQ_LEN,)) |
| embedding_layer = Embedding(VOCAB_SIZE, EMB_SIZE, input_length=MAX_SEQ_LEN)(input_layer) |
| dropout_emb = Dropout(rate=dropout_prob)(embedding_layer) |
| conv1 = Conv1D(filters=128, kernel_size=3, padding='valid', activation=tf.nn.relu)(dropout_emb) |
| pool1 = GlobalMaxPool1D()(conv1) |
| conv2 = Conv1D(filters=128, kernel_size=4, padding='valid', activation=tf.nn.relu)(dropout_emb) |
| pool2 = GlobalMaxPool1D()(conv2) |
| conv3 = Conv1D(filters=128, kernel_size=5, padding='valid', activation=tf.nn.relu)(dropout_emb) |
| pool3 = GlobalMaxPool1D()(conv3) |
| # 3, 4, 5- gram 이후 합치기 |
| concat = concatenate([pool1, pool2, pool3]) |
| hidden = Dense(128, activation=tf.nn.relu)(concat) |
| dropout_hidden = Dropout(rate=dropout_prob)(hidden) |
| logits = Dense(3, name='logits')(dropout_hidden) |
| predictions = Dense(3, activation=tf.nn.softmax)(logits) |
| # 모델 생성 |
| model = Model(inputs=input_layer, outputs=predictions) |
| model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) |
| # 모델 학습 |
| model.fit(train_ds, validation_data=val_ds, epochs=EPOCH, verbose=1) |
| # 모델 평가(테스트 데이터셋 이용) |
| loss, accuracy = model.evaluate(test_ds, verbose=1) |
| print('Accuracy: %f' % (accuracy * 100)) |
| print('loss: %f' % (loss)) |
| # 모델 저장 |
| model.save('cnn_model.h5') |
> BERT 모델
01 NLP에서의 사전 훈련
1. 사전 훈련된 워드 임베딩
임베딩을 사용하는 방법으로는 두 가지가 있다.
- 임베딩 층을 랜덤 초기화하여 처음부터 학습하는 방법.
- 방대한 데이터로 Word2Vec 등과 같은 임베딩 알고리즘으로 사전에 학습된 임베딩 벡터들을 가져와 사용하는 방법입니 다.
2. 사전 훈련된 언어 모델

우선 LSTM 언어 모델을 학습합니다. 언어 모델은 주어진 텍스트로부터 이전 단어들로부터 다음 단어를 예측하도록 학습하므로 기본적으로 별도의 레이블이 부착되지 않은 텍스트 데이터로도 학습 가능합니다.

ELMo는 순방향 언어 모델과 역방향 언어 모델을 각각 따로 학습시킨 후에, 이렇게 사전 학습된 언어 모델로부터 임베딩 값을 얻는다는 아이디어였습니다. 이러한 임베딩은 문맥에 따라서 임베딩 벡터값이 달라지므로, 기존 워드 임베딩인 Word2Vec이나 GloVe 등이 다의어를 구분할 수 없었던 문제점을 해결할 수 있었습니다.

위의 그림에서 Trm은 트랜스포머(Transformer)의 약자입니다. 트랜스포머의 디코더는 LSTM 언어 모델처럼 순차적으로 이전 단어들로부터 다음 단어를 예측합니다.

위의 좌측 그림에 있는 단방향 언어모델은 지금까지 배운 전형적인 언어 모델입니다. 시작 토큰 <SOS>가 들어가면, 다음 단어 I를 예측하고 그리고 그 다음 단어 am을 예측합니다. 반면, 우측에 있는 양방향 언어 모델은 지금까지 본 적 없던 형태의 언어 모델입니다. 실제로 이렇게 구현하는 경우는 거의 없는데 그 이유가 무엇일까요?
가령, 양방향 LSTM을 이용해서 우측과 같은 언어 모델을 만들었다고 해봅시다. 초록색 LSTM 셀은 순방향 언어 모델로 <sos>를 입력받아 I를 예측하고, 그 후에 am을 예측합니다. 그런데 am을 예측할 때, 출력층은 주황색 LSTM 셀인 역방향 언어 모델의 정보도 함께 받고있습니다. 그런데 am을 예측하는 시점에서 역방향 언어 모델이 이미 관측한 단어는 a, am, I 이렇게 3개의 단어입니다. 이미 예측해야하는 단어를 역방향 언어 모델을 통해 미리 관측한 셈이므로 언어 모델은 일반적으로 양방향으로 구현하지 않습니다.
02 BERT( 문맥을 양방향으로 이해해서 숫자로 바꿔주는 모델 )
1. BERT의 개요
BERT는 이전 챕터에서 배웠던 트랜스포머를 이용하여 구현되었으며, 위키피디아(25억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델입니다.
BERT가 높은 성능을 얻을 수 있었던 것은, 레이블이 없는 방대한 데이터로 사전 훈련된 모델을 가지고, 레이블이 있는 다른 작업(Task)에서 추가 훈련과 함께 하이퍼파라미터를 재조정하여 이 모델을 사용하면 성능이 높게 나오는 기존의 사례들을 참고하였기 때문입니다. 다른 작업에 대해서 파라미터 재조정을 위한 추가 훈련 과정을 파인 튜닝(Fine-tuning)이라고 합니다.
문맥을 양방향으로 이해해서 숫자로 바꿔주는 모델입니다. 예를들어 text란 단어가 있으면 이게 신문안에 있는 글자들을 의미하는 건지 문자 메세지를 보내는건지 헷갈릴 수 있습니다. 하지만 BERT은 어탠션 값을 이용하여 단어들 사이의 관계를 파악한후 text가 어떤 의미로 쓰였는지 파악할 수 있습니다.
비지도 학습 모델로 label이 없는 데이터로도 학습이 가능합니다. 단어를 예측하는 식으로 학습을 진행하기 때문에 질이 좋고 데이터의 양이 많으면 학습이 잘 진행될 수 있습니다. 가려진 단어를 학습니다.
트랜스포머의 인코더는 양방향으로 문맥을 이해하고, 디코더는 왼쪽에서부터 이해한다.